基本概念
顶点 (Vertex) :图中的数据元素。
边 (Edge) / 弧 (Arc)
无向图 (Undigraph) :边是无方向的,用 (v, w) 表示。如果 (v, w) 存在,则 v 和 w 互为邻接点。有向图 (Digraph) :弧是有方向的,用 <v, w> 表示,v 是弧尾(起点),w 是弧头(终点)。
度 (Degree)
无向图中,顶点 v 的度 TD(v) 是与它相连的边的数目。
有向图中,TD(v) = ID(v) + OD(v),其中 ID(v) 是入度(指向 v 的弧数),OD(v) 是出度(从 v 出发的弧数)。
推论:在任意图中,度数为奇数的点必然有偶数个。
路径 (Path) :从一个顶点到另一个顶点的顶点序列。路径上边或弧的数目称为路径长度。
连通性
无向图 :若任意两点间都有路径,则称为连通图 。非连通图的极大连通子图称为连通分量 。有向图 :若任意两点间都存在双向路径,则称为强连通图 。非强连通图的极大强连通子图称为强连通分量 。
生成树 (Spanning Tree) :对于一个无向连通图 ,其生成树是一个包含所有顶点、且只有 n-1 条边的极小连通子图(没有环)。非连通图的生成森林由其各个连通分量的生成树组成。
带权图/网 (Network) :每条边或弧都附加一个权值(如距离、费用、时间),权值可以表示从一个顶点到另一个顶点的代价。
数据结构 抽象地说,图 $Graph(Vertex, Edge)$ 其中 $Vertex, Edge$ 是两个集合, 包含了所有顶点与边。
边以三元组表示: $e=(u, v, w)$ 表示点$u$到点$v$权重为w的边。
点 1 2 3 4 5 6 7 8 9 10 struct Vertex { int v, w; Vertex (int _v, int _w): v (_v), w (_w) {} bool operator <(const Vertex &other) const { return w < other.w; } bool operator >(const Vertex &other) const { return w > other.w; } };
边 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct Edge { int u, v; int weight; Edge (int from, int to, int w): u (from), v (to), weight (w) {} bool operator <(const Edge &other) const { return weight < other.weight; } bool operator >(const Edge &other) const { return weight > other.weight; } bool operator ==(const Edge &other) const { return weight == other.weight && ((u == other.u && v == other.v) || (u == other.v && v == other.u)); } };
查找:全部遍历,比较uv。
在 Kruskal 算法 中,由于需要将边按边权排序,需要直接存边。
邻接矩阵 1 vector<vector<int >> martix;
使用matrix[u][v] = w 表示从$u$到$v$的有向 边。
邻接表 1 2 vector<vector<int >> martix; matrix.push_back ();
matrix[i] 表示点。
其中的元素表示终点与边权。
链式前向星 似乎不常用,暂时不展开
并查集 一个有多棵树的集合。同一颗树上的元素同属一个集合。
因此,图上同属一个树上的节点是连通的,但无法得知其方向 。
核心是维护一个vector,使用递归找到根节点。
注意 :并查集可用于检测无向图 的环,但无法检测有向图。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 struct dsu { vector<int > parent; vector<int > size; dsu (int _size){ parent.resize (_size); size.resize (_size, 1 ); for (int i=0 ; i<_size; i++){ parent[i] = i; } } int find (int u) if (parent[u] != u){ parent[u] = find (parent[u]); } return parent[u]; } bool unite (int u, int v) int u = find (u); int v = find (v); if (u == v){ return false ; } if (size[u] < size[v]){ swap (u, v); } parent[v] = u; size[u] += size[v]; return true ; } };
拓扑排序 一种对有向无环图节点排序的方法,需要维护入度数组,并取出入度为0的点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 vector<int > toposort (vector<vector<Vertex>> &graph) { int n = graph.size (); int cnt = 0 ; vector<int > res; vector<int > in_degree (n, 0 ) ; queue<int > q; for (auto &g: graph){ for (auto &v: g){ in_degree[v.v]++; } } for (int i = 0 ;i < n; ++i){ if (in_degree[i] == 0 ){ q.push (i); } } while (!q.empty ()){ cnt++; int u = q.front (); q.pop (); res.push_back (u); for (auto &v: graph[u]){ in_degree[v.v]--; if (in_degree[v.v] == 0 ){ q.push (v.v); } } } if (cnt != n){ return {}; } return res; }
关键路径 (CPM) 关键路径 是项目管理中用于确定项目最短完成时间的一组活动路径。它决定了整个项目的工期 —— 如果关键路径上的任何活动延迟,整个项目都会延迟。
故:CPM是针对有向图 上的问题,讲究事件的先后顺序。
需要使用 DP+拓扑排序 。
定义:
1 2 vector<int > earliest (n, 0 ) ; vector<int > latest (n, INT_MAX) ;
判定某个事件是“关键的”,关键在于 earliest[i] == latest[i] (下标表示节点)。而可以使用 latest[i]-earliest[i] 判断某个事件有多长的“浮动时间”,也就是说“还能在这个时间内安排其他事件”。因此,关键路径问题实际上是求关键事件的下标 。
主要过程
两次遍历图:找到每个事件发生的最早时间和最晚时间
由于是求最优问题,因此需要考虑 DP
由于需要让整个项目工期最短 ,因此需要先找到最晚发生的事件的最早发生时间 ($min(max)$ 问题)
求每个事件最早发生时间需要前向求解 ,求每个事件最晚发生时间需要从最后一个事件的最优情况开始反向求解 。
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int CPM (vector<vector<Vertex>> &graph) int n = graph.size (); vector<int > topo = toposort (graph); vector<int > earliest (n, 0 ) ; vector<int > latest (n, INT_MAX) ; for (auto from: topo){ for (auto &v: graph[from]){ auto [to, w] = v; earliest[to] = max (earliest[to], earliest[from] + w); } } latest[topo.back ()] = earliest[topo.back ()]; for (auto it = topo.rbegin (); it != topo.rend (); ++it) { auto from = *it; for (auto &v: graph[from]){ auto [to, w] = v; latest[from] = min (latest[from], latest[to] - w); } } return earliest[topo.back ()]; }
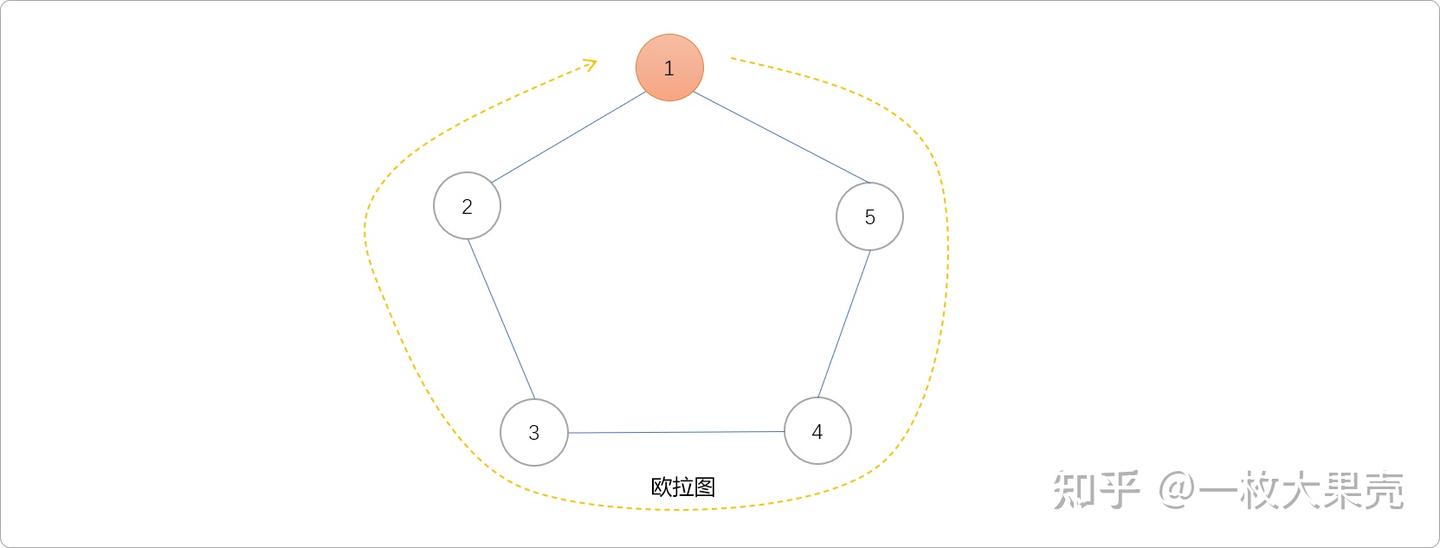
欧拉图 (摘自知乎回答)
欧拉回路:指在图(无向图或有向图)中,经过图中所有边且只经过边一次所形成的回路,称为欧拉回路。具有欧拉回路的图称为欧拉图。如下图结构为欧拉图,从1号节点出发,经过所有边后可以重回到1号节点。
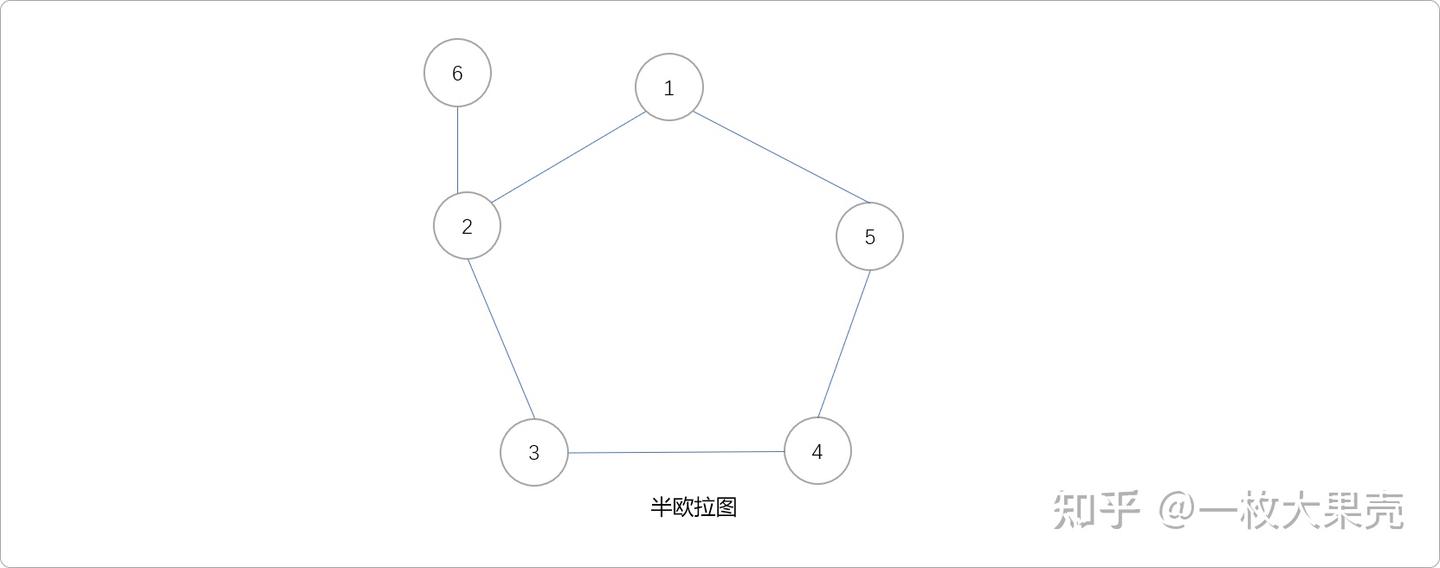
欧拉路径:指通过图中每条边且仅通过一次形成的路径(没有环)。具有欧拉路径但不具有欧拉回路的图称为半欧拉图 。如下图,从6号节点出发,可以经过每一条边后到达2号节点,存在欧拉路径,只能说是半欧拉图。
一个图是欧拉图,当且仅当所有顶点的度数都是偶数 。
一个图是半欧拉图,当且仅当只有一个顶点的度数是奇数 。
由此可以解决一笔画 相关问题。题目描述是:给出边,判断图是否能够在不经过重复边的情况下遍历(遍历特指走过每一条边 )。按照欧拉图的性质,问题就可以分解为:
图是否连通 (使用Union-Find)是否为半欧拉图 (要么都是偶度数节点,要么只有一个奇度数节点。如果有奇度数节点,起点必须是这个点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 bool is_euler () int n, m; cin>>n>>m; vector<int > degree (n+1 ) ; int odd = 0 ; for (int i = 0 ; i < m; ++i){ int from, to; cin>>from>>to; degree[from]++; degree[to]++; union (from, to); } for (int i = 1 ; i < n; ++i){ if (find (i) != find (i+1 )){ return false ; } } for (auto d: degree){ if (d % 2 ){ odd++; } if (odd > 1 ){ return false ; } } return true ; }
生成树 树是由$n$个节点、 $n-1$条边构成的数据结构。生成树,就相当于把图中的边删除,直到剩余$n-1$条边。
使用邻接矩阵表示图,DFS生成树的实现如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 vector<vector<int >> spanning_tree (vector<vector<int >> &graph){ int n = graph.size (); vector<vector<int >> tree (n, vector <int >(n, 0 )); vector<bool > vis (n, false ) ; function<void (int )> dfs = [&](int u){ vis[u] = true ; for (int v = 0 ; v < n; v++){ if (graph[u][v] != 0 && !vis[v]){ tree[u][v] = graph[u][v]; tree[v][u] = graph[u][v]; dfs (v); } } }; dfs (0 ); return tree; }
生成森林 非连通图,相当于构造多棵树,实现原理与生成树类似。
最小生成树(MST) 最小生成树(MST)主要用来解决”以最小总成本连接所有节点”这类优化问题 。
Prim 适用于有向图
基本思想
从任意顶点开始,逐步扩展生成树
每次选择连接已选顶点集 和未选顶点集 的最小权重边
直到所有顶点都包含在生成树中
使用的加点法与 Dijkstra 类似
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 int prim (vector<vector<Vertex>> &graph) int costs = 0 ; int vertex_cnt = 0 ; priority_queue<Vertex, vector<Vertex>, greater<Vertex>> pq; vector<bool > vis (graph.size(), false ) ; vector<int > dis (graph.size(), INT_MAX) ; dis[0 ] = 0 ; pq.push (Vertex (0 , 0 )); while (!pq.empty ()){ Vertex cur = pq.top (); int v = cur.v; int w = cur.w; pq.pop (); if (vis[v]){ continue ; } vis[v] = true ; vertex_cnt++; costs += w; for (auto &next: graph[v]){ if (!vis[next.v] && dis[next.v] > next.w){ dis[next.v] = next.w; pq.push (Vertex (next.v, next.w)); } } } return costs; }
Kruskal 基本思想
按照边的权重从小到大排序
依次选择边,如果加入该边不会形成环,则加入生成树
直到选择了 n-1 条边(n为顶点数)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 vector<Edge> kruskal (vector<Edge> &edges, int n) { int costs = 0 ; int edge_count = 0 ; sort (edges.begin (), edges.end ()); dsu d (n+1 ) ; vector<Edge> result; for (const auto &edge: edges){ if (d.find (edge.u) != d.find (edge.v)){ d.unite (edge.u, edge.v); result.push_back (edge); costs += edge.weight; edge_count++; } } for (const auto &edge: result){ cout<<edge.u<<" - " <<edge.v<<" : " <<edge.weight<<endl; } return result; }
最短路径 Floyd 适用于任何图,不管有向无向,边权正负,但是最短路必须存在。(不能有个负环)
核心思想是借助辅助点k,贪心地更新最短距离。适用邻接矩阵。
若记录路径,需要额外定义前驱bool张量 $path[i][j][k]$ 表示:k 是从 i 到 j 最短路径上的顶点 (说明路径满足$v_i \xrightarrow{somevex} v_k \xrightarrow{somevex} v_j$)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 vector<vector<int >> floyd (vector<vector<int >> &graph){ vector<vector<int >> dis_matrix = graph; vector<vector<vector<bool >>> path ( n, vector<vector<bool >>(n, vector <bool >(n, false ))); for (int i = 0 ; i < n; i++){ for (int j = 0 ; j < n; j++){ if (i == j){ path[i][j][i] = true ; } else if (graph[i][j] < INT_MAX){ path[i][j][i] = true ; path[i][j][j] = true ; } } } int n = graph.size (); for (int k = 0 ; k < n; k++){ for (int i = 0 ; i < n; i++){ for (int j = 0 ; j < n; j++){ if (dis_matrix[i][k] + dis_matrix[k][j] < dis_matrix[i][j]){ dis_matrix[i][j] = dis_matrix[i][k] + dis_matrix[k][j]; for (int v = 0 ; v < n; v++){ path[i][j][v] = path[i][k][v] || path[k][j][v]; } path[i][j][i] = true ; path[i][j][j] = true ; } } } } return dis_matrix; }
Bellman-Ford Bellman–Ford 算法是一种基于松弛(relax)操作的最短路算法,可以求出有负权的图的最短路,并可以对最短路不存在的情况进行判断。
松弛操作:对于边 (𝑢,𝑣),松弛操作对应下面的式子:𝑑𝑖𝑠(𝑣)=min(𝑑𝑖𝑠(𝑣),𝑑𝑖𝑠(𝑢) +𝑤(𝑢,𝑣))。
适用边列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 vector<int > bellman_ford (vector<Edge> &edges, int n, int start) { vector<int > dist (n+1 , INT_MAX) ; dist[start] = 0 ; bool flag = false ; for (int i = 0 ; i < n; ++i){ flag = false ; for (auto &edge: edges){ int u = edge.u; int v = edge.v; int w = edge.weight; if (dist[u] != INT_MAX && dist[u] + w < dist[v]){ dist[v] = dist[u] + w; flag = true ; } } if (!flag){ break ; } } if (flag){ return {}; } return dist; }
SPFA Bellman-Ford优化,避免检查多余负权环
Dijkstra 求解 非负权图 上单源最短路径的算法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vector<int > dijkstra (vector<vector<Vertex>> &graph, int start) { int n = graph.size (); vector<int > dist (n, INT_MAX) ; vector<int > parent (n, -1 ) ; vector<bool > vis (n+1 , false ) ; dist[start] = 0 ; priority_queue<Vertex, vector<Vertex>, greater<Vertex>> pq; pq.push (Vertex (start, 0 )); while (!pq.empty ()){ auto [v, w] = pq.top (); vis[v] = true ; pq.pop (); for (auto &next: graph[v]){ if (!vis[next.v] && dist[v] + next.w < dist[next.v]){ dist[next.v] = dist[v] + next.w; parent[next.v] = v; pq.push (Vertex (next.v, dist[next.v])); } } } return dist; }
Astar 最近做游戏用到的一种寻路算法,因此使用C#描述。
Node.cs 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 using System.Collections;using UnityEngine;public class Node { public bool isWalkable; public Vector3 worldPosition; public int gridX; public int gridY; public float height; public Node parent; public int gCost; public int hCost; public int fCost => gCost + gCost; public Node (Vector3 _worldPos, int _gridX, int _gridY, bool _isWalkable ) isWalkable = _isWalkable; worldPosition = _worldPos; gridX = _gridX; gridY = _gridY; } }
RTSGrid.cs 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 using System;using System.Collections.Generic;using UnityEngine;public class RTSGrid : MonoBehaviour { public LayerMask layerMask; public Vector2 gridWorldSize; public float nodeRadius; private Node[,] grid; private int gridSizeX, gridSizeY; private float nodeDiameter; void Awake () nodeDiameter = nodeRadius * 2 ; gridSizeX = Mathf.RoundToInt(gridWorldSize.x / nodeDiameter); gridSizeY = Mathf.RoundToInt(gridWorldSize.y / nodeDiameter); CreateGrid(); } void CreateGrid () grid = new Node[gridSizeX, gridSizeY]; Vector3 worldBottomLeft = transform.position - Vector3.right * gridWorldSize.x / 2 - Vector3.forward * gridWorldSize.y / 2 ; for (int x = 0 ; x < gridSizeX; x++) { for (int y = 0 ; y < gridSizeY; y++) { Vector3 worldPoint = worldBottomLeft + Vector3.right * (x * nodeDiameter + nodeRadius) + Vector3.forward * (y * nodeDiameter + nodeRadius); bool isWalkable = !Physics.CheckSphere(worldPoint, nodeRadius, layerMask); grid[x, y] = new Node(worldPoint, x, y, isWalkable); } } } public List<Node> GetNeighbors (Node node ) List<Node> neighbors = new List<Node>(); for (int x = -1 ; x <= 1 ; x++) { for (int y = -1 ; y <= 1 ; y++) { if (x == 0 && y == 0 ) { continue ; } int getX = node.gridX + x; int getY = node.gridY + y; if (getX >= 0 && getX < gridSizeX && getY >= 0 && getY < gridSizeY) { neighbors.Add(grid[getX, getY]); } } } return neighbors; } public Node GetNodeFromWorldPoint (Vector3 worldPosition ) float percentX = (worldPosition.x + gridWorldSize.x / 2 ) / gridWorldSize.x; float percentY = (worldPosition.z + gridWorldSize.y / 2 ) / gridWorldSize.y; return grid[Mathf.RoundToInt(Mathf.Clamp01(percentX) * (gridSizeX - 1 )), Mathf.RoundToInt(Mathf.Clamp01(percentY) * (gridSizeY - 1 ))]; } }
PathFinder.cs 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 using System;using System.Collections.Generic;using UnityEngine;public class FindPathAstar : MonoBehaviour { RTSGrid grid; private void Awake () grid = GetComponent<RTSGrid>(); } public List<Node> FindPath (Vector3 startWorldPos, Vector3 targetWorldPos ) Node startNode = grid.GetNodeFromWorldPoint(startWorldPos); Node targetNode = grid.GetNodeFromWorldPoint(targetWorldPos); List<Node> openSet = new List<Node>(); HashSet<Node> closedSet = new HashSet<Node>(); openSet.Add(startNode); while (openSet.Count > 0 ) { Node currentNode = openSet[0 ]; for (int i = 1 ; i < openSet.Count; i++) { if (openSet[i].fCost < currentNode.fCost || openSet[i].fCost == currentNode.fCost && openSet[i].hCost < currentNode.hCost) { currentNode = openSet[i]; } } openSet.Remove(currentNode); closedSet.Add(currentNode); if (targetNode == currentNode) { return RetracePath(startNode, targetNode); } foreach (var node in grid.GetNeighbors(currentNode)) { if (!node.isWalkable || closedSet.Contains(node)) { continue ; } int newMovementCostToNeighbour = currentNode.gCost + GetDistance(currentNode, node); if (newMovementCostToNeighbour < node.gCost || !closedSet.Contains(node)) { node.gCost = newMovementCostToNeighbour; node.hCost = GetDistance(node, targetNode); node.parent = currentNode; if (!openSet.Contains(node)) { openSet.Add(node); } } } } return null ; } private List<Node> RetracePath (Node startNode, Node endNode ) List<Node> path = new List<Node>(); Node currentNode = endNode; while (currentNode != startNode) { path.Add(currentNode); currentNode = currentNode.parent; } path.Reverse(); return path; } private int GetDistance (Node a, Node b ) int dx = Mathf.Abs(a.gridX - b.gridX); int dy = Mathf.Abs(a.gridY - b.gridY); return Mathf.Min(dx, dy) * 10 + Mathf.Abs(dx - dy) * 14 ; } }